Validating PhoSim
| A plot of the averaged intensity of simulated images (diamonds) to real data (triangles) as a function of time. The different colors represent what filter was used to simulate the image |
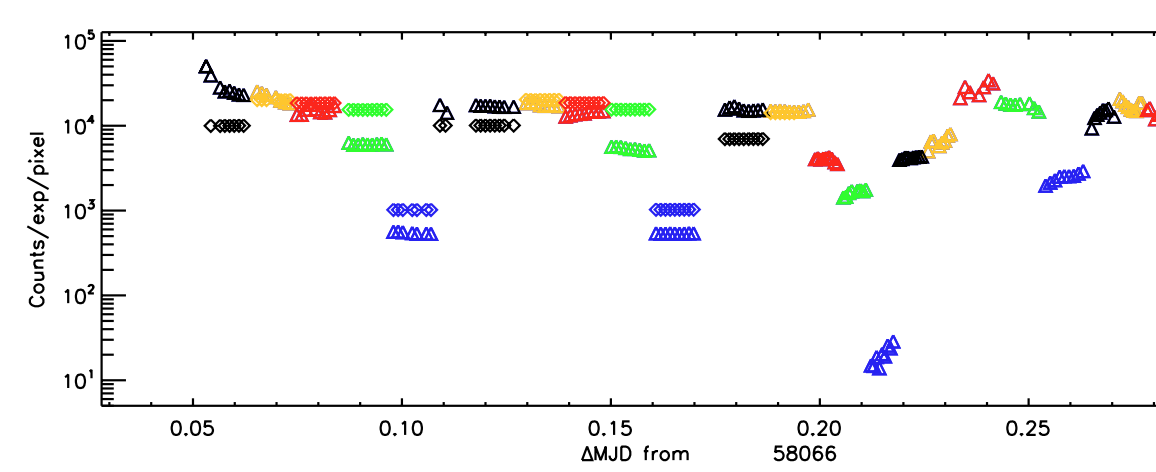
One of my larger projects involved with PhoSim was making a pipeline to validate our simulated data of a specific telescope by making quantitative comparisons to real data of that same telescope. I did this by first specifying what exactly our simulated telescope was looking at. This is accomplished by editing "catalog files" that PhoSim reads and interprets into data about what it is looking at. Since we required a large amount of data, I had to write a Python script that would build these catalog files for me. After building the files, I would run PhoSim to simulate the telescope images and collect statistics about each image such as the median of the average pixel value, which is related to the intensity of the image. These statistics would then be written into a text file to be later read by the plotting program.
After simulating the images and collecting the statistics into a test file, my pipeline would then repeat an (almost) identical process for our collection of real images, with the obvious exception of not having to simulate them. After collecting data on both the simulated and real images, the pipeline would then use the programming language IDL to plot the intensity of each image as a function of time. From these plots, we can draw conclusions about how accurate our simulations are based on how well the simulated data follows the trends of the real data. The actual intensity values don't matter, so long as the trends are the same.
In short, this pipeline simulates telescope images given data from a real telescope, then calculates important statistics about both the real and simulated images to draw conclusions about how accurate the simulations are to reality.
A logistical challenge of this project was storage space. Astronomical images are very often in the tens of gigabyte range of disk space, and I had hundreds to process. As a result, it was not feasible to have access to every image at once. As a solution, I simply had the pipeline download the image as it was needed using the Unix command wget, calculate the needed data from the image, then dispose of the image to make space for the next image.
Skills applied: Python, IDL, C++, BASH